
گویا مصرف برق پردازندههای نسل آینده هوش مصنوعی ۱۵۰ تا ۳۶۰ وات و برخی مدلها حتی تا ۱۰۰۰ وات یا فراتر باشد.
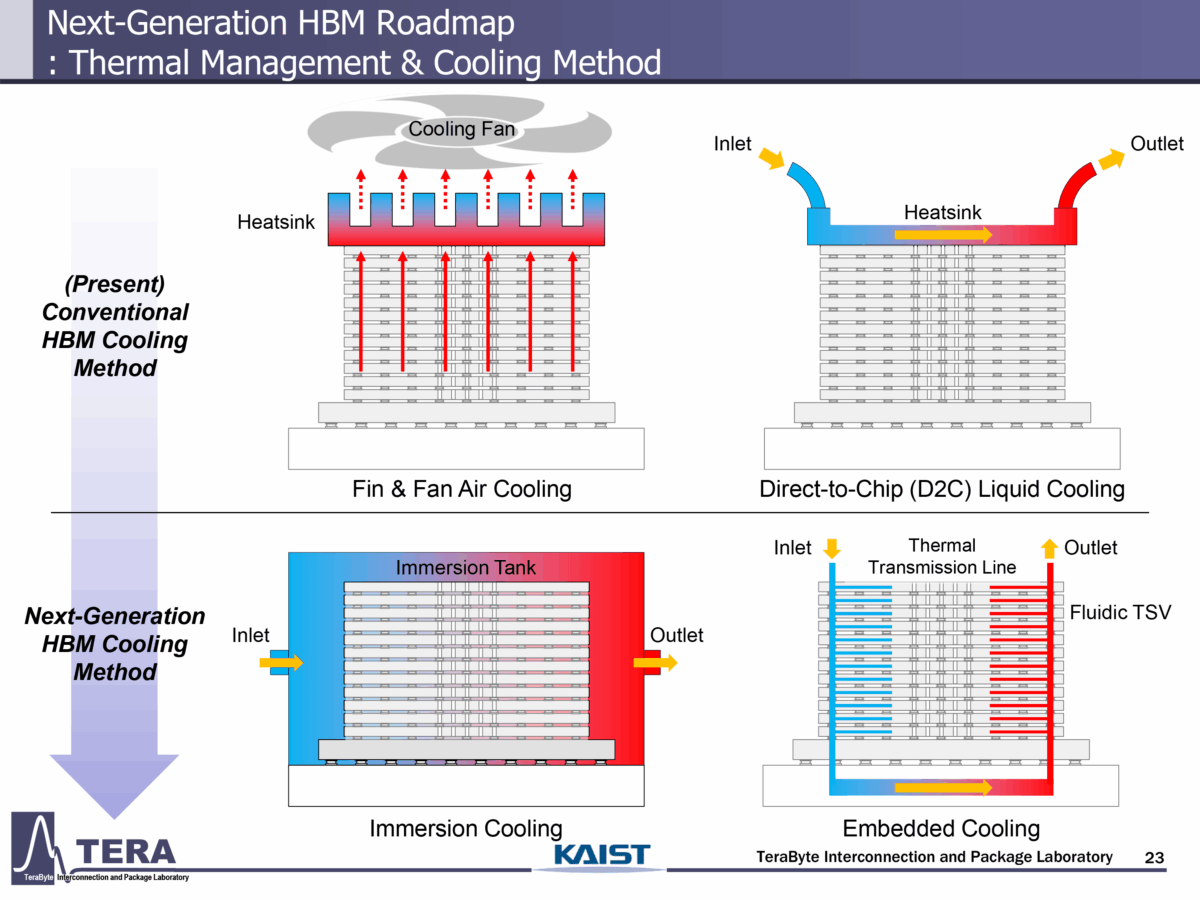
به گزارش تکناک و به نقل از پژوهشگران مؤسسه KAIST کرهجنوبی، نسلهای آینده پردازندههای هوش مصنوعی با افزایش چشمگیر مصرف انرژی مواجه خواهند شد که استفاده از فناوریهای نوین خنککنندگی مانند سیستمهای غوطهوری و خنککنندگی جاسازیشده را ضروری میکند.

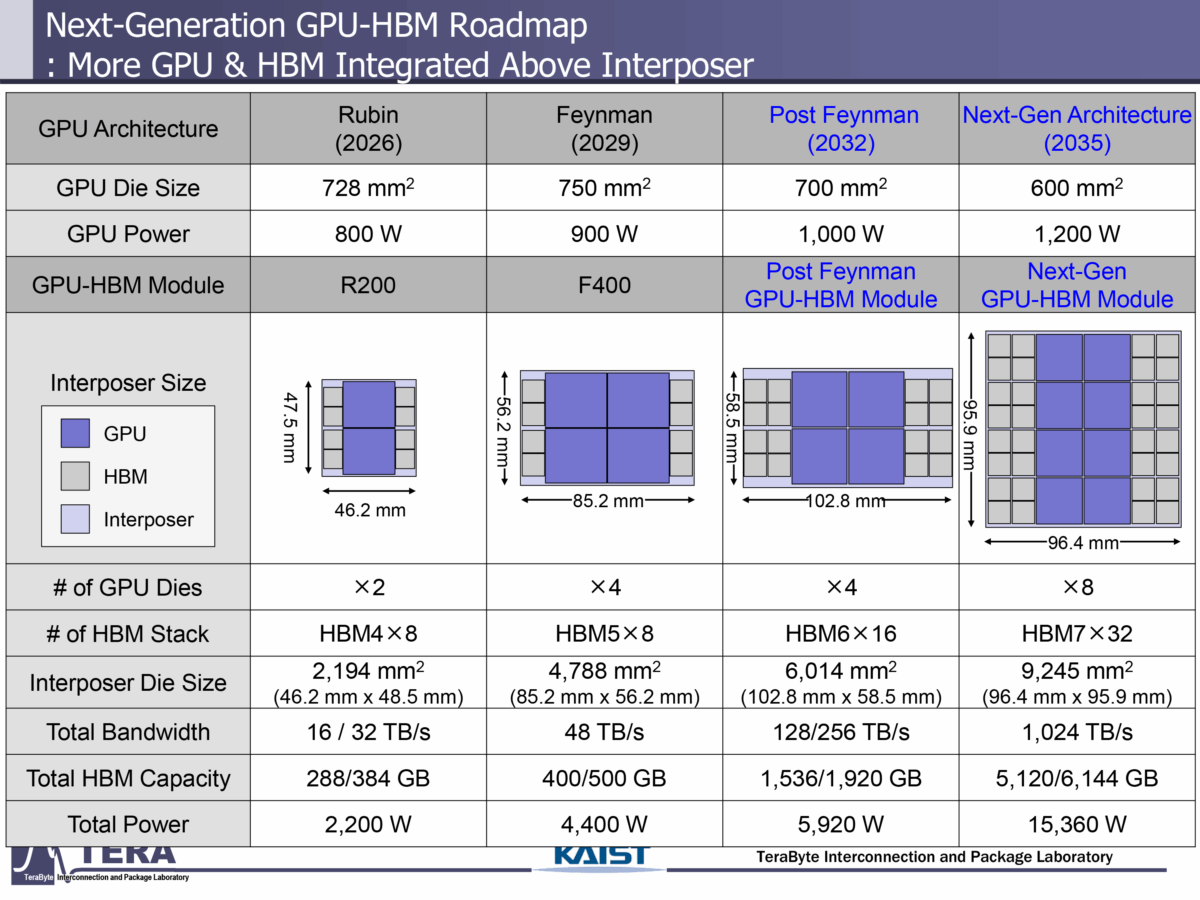
براساس این پیشبینیها، توان طراحی حرارتی (TDP) پردازندههای هوش مصنوعی در ده سال آینده به عدد خیرهکننده ۱۵,۳۶۰ وات خواهد رسید. این رقم بسیار فراتر از مقدار فعلی پردازندههای پیشرفته انویدیا است که درحالحاضر، از روشهای خنککنندگی با مایع مستقیم به چیپ (D2C) بهره میبرند.
تامزهاردور مینویسد که در سالهای اخیر، مصرف انرژی GPUهای هوش مصنوعی بهدلیل استفاده از چیپلتهای محاسباتی و حافظههای HBM بهطور مداوم افزایش یافته است. منابع مطلع اعلام کردند که انویدیا در نسلهای بعدی پردازندههای خود برای توان طراحی حرارتی ۶,۰۰۰ تا ۹,۰۰۰ وات برنامهریزی کرده است؛ اما پژوهشگران KAIST این عدد را تا ۱۵,۳۶۰ وات در سالهای آینده پیشبینی میکنند.
جدول پیشبینی توان مصرفی و روش خنککنندگی نسلهای آینده GPUهای هوش مصنوعی:
| نسل پردازنده | سال عرضه | توان کل بسته GPU | روش خنککنندگی |
| Blackwell Ultra | ۲۰۲۵ | ۱,۴۰۰ وات | خنککنندگی مایع مستقیم به چیپ (D2C) |
| Rubin | ۲۰۲۶ | ۱,۸۰۰ وات | D2C |
| Rubin Ultra | ۲۰۲۷ | ۳,۶۰۰ وات | D2C |
| Feynman | ۲۰۲۸ | ۴,۴۰۰ وات | خنککنندگی غوطهوری |
| Feynman Ultra | ۲۰۲۹ | ۶,۰۰۰ وات | خنککنندگی غوطهوری |
| Post-Feynman | ۲۰۳۰ | ۵,۹۲۰ وات | خنککنندگی غوطهوری |
| Post-Feynman Ultra | ۲۰۳۱ | ۹,۰۰۰ وات | خنککنندگی غوطهوری |
| ? | ۲۰۳۲ | ۱۵,۳۶۰ وات | خنککنندگی جاسازیشده |
کارشناسان پیشبینی میکنند که در نسل Feynman، میزان اتلاف حرارت به ۴,۴۰۰ وات برسد و در نسخه Feynman Ultra این عدد حتی به ۶,۰۰۰ وات افزایش یابد. در این شرایط، تنها راهکار مؤثر برای کنترل دما، خنککنندگی غوطهوری خواهد بود که در آن کل ماژولهای GPU و HBM در مایع حرارتی مخصوص غوطهور میشوند.
علاوهبر این، انتظار میرود در این پردازندهها از فناوریهای پیشرفته مانند مسیرهای حرارتی عمودی (TTV) برای هدایت گرما از بستر سیلیکونی و لایههای اتصال حرارتی و حسگرهای دمایی جاسازیشده در پایههای ماژول HBM استفاده شود که امکان کنترل و پایش لحظهای دما را فراهم میکند.
گزارشها حاکی است که روش خنککنندگی غوطهوری تا سال ۲۰۳۲ پاسخگوی نیازهای حرارتی خواهد بود؛ اما پساز آن و با عرضه معماریهای Post-Feynman، توان طراحی حرارتی به ۵,۹۲۰ و حتی ۹,۰۰۰ وات خواهد رسید که خنککنندگی جاسازیشده به الزام تبدیل میشود.
یکی از نکات درخورتوجه این است که در نسلهای جدید، مصرف انرژی چیپلتهای حافظه نیز افزایش چشمگیری خواهد یافت؛ بهگونهای که با افزایش تعداد پشتههای HBM به ۱۶ عدد و مصرف ۱۲۰ وات برای هر پشته در حافظه HBM6، مجموع مصرف انرژی حافظه به ۲,۰۰۰ وات خواهد رسید که تقریباً معادل یکسوم کل مصرف انرژی بسته GPU است.
براساس پیشبینیهای KAIST، تا سال ۲۰۳۵ مصرف انرژی پردازندههای هوش مصنوعی به مرز ۱۵,۳۶۰ وات خواهد رسید که در این صورت استفاده از ساختارهای خنککنندگی جاسازیشده برای هر دو بخش محاسباتی و حافظه ضروری خواهد شد.
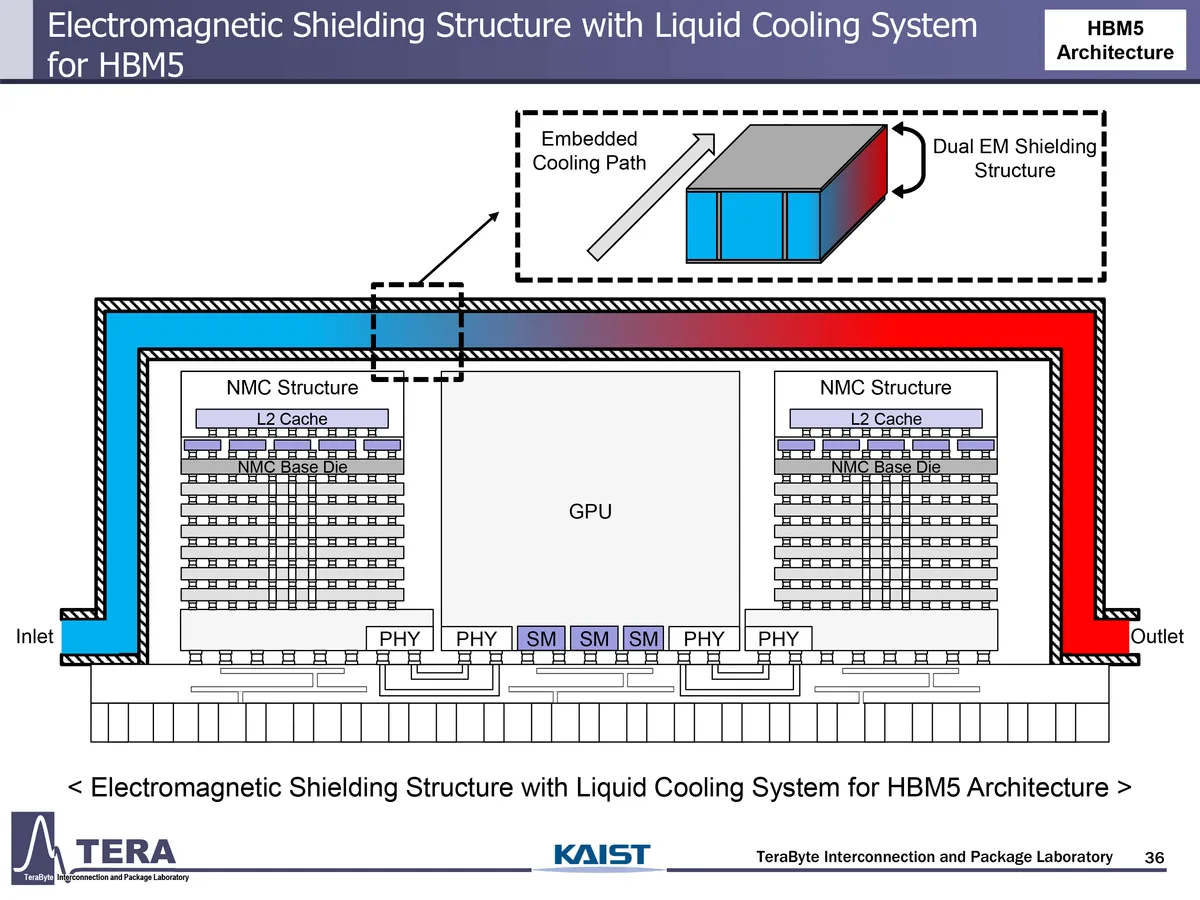
دو فناوری مهم در این مسیر معرفی خواهند شد: خطوط انتقال حرارتی (TTLها) که گرما را بهصورت جانبی از نقاط داغ به رابطهای خنککننده منتقل میکنند و TSVهای سیال (F-TSVها) که اجازه میدهند مایع خنککننده بهصورت عمودی در میان پشتههای HBM جریان یابد. این فناوریها بهطور مستقیم در بستر سیلیکونی و اینترپوزر ادغام خواهند شد.
تا سال ۲۰۳۸، پیشبینی میشود که راهکارهای حرارتی کاملاً یکپارچه و گستردهتر و پیشرفتهتر شوند. در این راهکارها، از اینترپوزرهای دوطرفه استفاده خواهد شد تا امکان پشتهسازی عمودی در هر دو طرف فراهم شود؛ درحالیکه خنککنندگی سیال نیز در سراسر آن جاسازی شده است. همچنین، معماریهای GPU-on-top به اولویتدادن به دفع حرارت از لایه محاسباتی کمک خواهند کرد و TSVهای هممحور نقش متعادلسازی بین جریان سیگنال و حرارت را ایفا خواهند کرد.
در پایان، باید گفت که افزایش چشمگیر توان و مصرف انرژی پردازندههای هوش مصنوعی در سالهای آینده، صنعت سختافزار را به توسعه فناوریهای خنککنندگی کاملاً جدید و پیشرفته ناگزیر خواهد کرد. راهکارهایی که تاکنون فقط در مراکز تحقیقاتی مطرح بودند، بهزودی به الزام فنی در طراحی پردازندههای تجاری تبدیل خواهند شد.





















