
از کوانتوم تا کد؛ با ۱۰ الگوریتم جادویی و شگفتانگیز تاریخ آشنا شوید
آیا تا به حال فکر کردهاید که چطور تصاویر سهبعدی دقیق پزشکی از دل دادههای اسکن بیرون میآیند؟ یا چگونه هوش مصنوعی میتواند از یک توضیح متنی، تصویری خلاقانه بسازد؟ پاسخ در دنیای شگفتانگیز الگوریتمها نهفته است.
از الگوریتم «Marching Cubes» که در سال ۱۹۸۷ انقلابی در تصویربرداری پزشکی بهپا کرد و به پزشکان اجازه داد مدلهای سهبعدی بدن را ببینند، تا الگوریتم «Diffusion» که قلب تپندهی ابزارهای تولید تصویر مانند DALL-E و میدجرنی است، الگوریتمها فراتر از دستورات ساده به کامپیوتر هستند. آنها ابزارهایی خلاقانه، سریع و گاهی عجیباند که مرزهای تخیل و مهندسی را جابجا کردهاند.
- خلاصه پادکستی مقاله
- الگوریتم فروپاشی تابع موج برای خلق واقعیتهای مجازی
- الگوریتم Diffusion برای توسعه هوش مصنوعی
- الگوریتم بازپخت شبیهسازی شده برای جستوجوی هوشمند
- الگوریتم Sleep Sort برای مرتبسازی در خواب
- الگوریتم مرتبسازی ساختگی (Bogo Sort)
- الگوریتم RSA؛ امنیت دیجیتال در برابر تهدید کوانتوم
- الگوریتم Marching Cubes برای ساخت مدل سهبعدی بدن
- الگوریتم PBFT برای امنیت بلاکچین
- الگوریتم Boids برای شبیهسازی پرواز پرندگان
- الگوریتم Boyer-Moore برای برنامهنویسها
بهزبان ساده، هر زمان که از کامپیوتر خواستهایم تا مسئلهای را مرحلهبهمرحله حل کند، در واقع برای آن یک الگوریتم نوشتهایم. الگوریتم یعنی مجموعهای منظم از دستورالعملها که به کامپیوتر میگوید چه کاری را، چطور و به چه ترتیبی انجام دهد. بسیاری از کارهایی که امروزه بهصورت خودکار انجام میشوند، از مرتبسازی فهرستها تا تشخیص چهره یا ترجمهی متن، همگی بهلطف همین الگوریتمها ممکن شدهاند.
خلاصه پادکستی مقاله
خلاصهشده با هوش مصنوعی
البته همهی الگوریتمها به یک اندازه ارزشمند نبودهاند. برخی از آنها فقط در حد تمرین برنامهنویسی باقی ماندهاند، اما برخی دیگر بهاندازهای سریع، خلاقانه یا حتی عجیب و پیچیده بودهاند که دانشمندان آنها را چیزی شبیه به جادو دانستهاند. الگوریتمهایی وجود دارند که میتوانند تصاویر تار را واضح یا صداهای ناقص را بازسازی کنند. بعضی دیگر از روی اطلاعات دوبُعدی، مدلهای سهبعدی میسازند. اینها فقط مجموعهای از دستورات ماشینی و بیروح نیستند؛ بلکه ابزارهایی هستند که توانستهاند راه ما را برای دیدن، شنیدن و حتی درمان کردن تغییر دهند.
در این مطلب، با هم به سراغ ۱۰ الگوریتم شگفتانگیز و غیرمعمول میرویم که هرکدام بهنحوی مرزهای تخیل و مهندسی را جابهجا کردهاند.
الگوریتم فروپاشی تابع موج برای خلق واقعیتهای مجازی
یکی از عجیبترین آزمایشهای علمی در فیزیک مدرن، آزمایش دوشکاف است که نشان میدهد ذرهای مانند الکترون، وقتی کسی آن را مشاهده نمیکند، مانند موج رفتار میکند؛ اما بهمحض اینکه بخواهیم مسیرش را دنبال کنیم، ناگهان تغییر رفتار میدهد و مانند یک ذرهی معمولی ظاهر میشود.


این پدیده در فیزیک کوانتوم با نام «فروپاشی تابع موج» (Wave Function Collapse) شناخته میشود. یعنی در دنیای کوانتوم، تا زمانی که چیزی را مشاهده نکنیم، آن چیز در مجموعهای از حالتهای ممکن قرار دارد. اما بهمحض مشاهده، یکی از حالتها، واقعی میشود و بقیه ناپدید میشوند یا فرو میپاشند.
در نگاه اول، چنین رفتاری ممکن است کاملاً غیرمنطقی بهنظر برسد؛ اما برخی افراد، با نگاهی فلسفی یا حتی طنزآمیز، این پدیده را اینگونه توصیف کردهاند: شاید جهان ما شبیه به یک بازی یا شبیهسازی کامپیوتری باشد که فقط زمانی بخشهایی از محیط را نمایش میدهد که به آن نگاه میکنیم؛ درست مثل بازیهای کامپیوتری که برای صرفهجویی در منابع، فقط بخشهایی را که جلوی چشم بازیکن هستند، پردازش میکنند.
الگوریتم WFC به کامپیوتر اجازه میدهد جهانی خلق کند که تنها هنگام دیده شدن، به واقعیت میپیوندد
ایدهی فروپاشی تابع موج فقط یک موضوع علمی یا فلسفی نیست، بلکه الهامبخش یکی از خلاقانهترین الگوریتمهای تولید محتوا در دنیای برنامهنویسی شده است؛ الگوریتمی با نام الگوریتم فروپاشی تابع موج (Wave Function Collapse Algorithm یا WFA). این الگوریتم به برنامهنویسان اجازه میدهد تا بتوانند نقشهها، بافتها یا محیطهای پیچیده را بهصورت رویهای و بدون تکرار تولید کنند (مثلاً برای بازیهایی با نقشههای بزرگ و بیپایان).
فرض کنید قرار است برای یک بازی، نقشهای تولید شود که هر بار که بازیکن وارد آن میشود، جدید و متفاوت باشد. نمیتوان این نقشه را از قبل بهصورت کامل طراحی کرد، چون بیشازحد بزرگ است یا اصلاً هیچ پایانی ندارد. بنابراین، باید الگوریتمی نوشته شود که خودش در لحظه تصمیم بگیرد؛ اما این تصمیمگیری، نباید کاملاً تصادفی باشد، بلکه باید منطقی و قانونمند انجام شود.
الگوریتم WFC در آغاز فرض میکند که هر بخش از نقشه میتواند هر چیزی باشد؛ یعنی تمام حالتهای ممکن برای آن باز هستند؛ درست مثل وضعیت برهمنهی (Superposition) در فیزیک کوانتوم، جایی که ذره میتواند همزمان در چند حالت مختلف قرار داشته باشد. سپس الگوریتم، با توجه به موقعیت و اطلاعات اطراف، تصمیم میگیرد که آن نقطه چه باید باشد: جاده؟ دیوار؟ درخت؟ یا خانه؟
بهمحض اینکه یک انتخاب انجام شود، امکانهای موجود برای خانههای اطراف محدودتر میشوند، چون باید با بخش انتخابشده سازگار باشند. این فرایند بهصورت گامبهگام ادامه پیدا میکند و هر مرحله، آزادی انتخاب را در نقاط بَعدی کمتر میکند، تا اینکه در نهایت یک نقشهی کامل و منسجم ساخته میشود؛ بدون نیاز به طراحی دستی یا تولید تصادفی بیقاعده.
در این فرایند، تنها کافی است قوانین سادهای مشخص شده باشند، مثلاً جادهها باید به یکدیگر متصل باشند یا خانه نمیتواند وسط دریا قرار داشته باشد. همین چند قانون ساده کافی هستند تا الگوریتم بدون کمک مستقیم انسان، محیطی سازگار، متنوع و طبیعی تولید کند. درنهایت، بهکمک ایدهای که از فیزیک کوانتوم الهام گرفته شده است، دنیایی مجازی ساخته میشود که هر بار بهشکلی تازه، مقابل چشم کاربر شکل میگیرد؛ مثل جهانی که فقط وقتی به آن نگاه میکنید، وجود پیدا میکند.
الگوریتم Diffusion برای توسعه هوش مصنوعی
هوش مصنوعی بهتنهایی آنقدر عجیب و شگفتانگیز است که ما را حیرتزده کند، اما وقتی به الگوریتمی به نام انتشار یا دیفیوژن (Diffusion) میرسیم، ماجرا پیچیدهتر میشود. این الگوریتم، یکی از نوآورانهترین روشهایی است که برای تولید تصویر بهکمک ماشین طراحی شده و مغز متفکر ابزارهایی مانند DALL-E و Stable Diffusion بهشمار میرود.
الگوریتم دیفیوژن از مفهومی در ترمودینامیک گرفته شده است. در فیزیک، انتشار به پدیدهای گفته میشود که در آن ذرات از ناحیهای با غلظت بالا به ناحیهای با غلظت پایین پخش میشوند؛ مثل عطری که در فضای اتاق پخش میشود؛ اما در دنیای هوش مصنوعی، ماجرا برعکس است: الگوریتم انتشار از یک وضعیت کاملاً بینظم و پر از نویز شروع و بهتدریج پالایش میشود تا به یک تصویر منظم، شفاف و معنادار برسد.
این الگوریتم، ابتدا تصویری کاملاً تصادفی و پر از نویز تولید میکند، تصویری پر از نقطههای بیمعنا و آشفته، چیزی شبیه آشوب کامل. این وضعیت را میتوان حالتی با آنتروپی بالا در نظر گرفت، یعنی جایی که هیچ نظم و ساختاری وجود ندارد. سپس، الگوریتم با کمک یک مدل آموزشدیده، این تصویر بینظم را گامبهگام اصلاح میکند و بهتدریج به آن شکل، ساختار و معنا میبخشد.
در پایان، نویز خام ابتدایی به تصویری واقعی و قابل درک تبدیل میشود، حالتی با آنتروپی پایین. اما برای اینکه چنین تغییری ممکن شود، ابتدا باید مدل را آموزش داد. این آموزش در دو مرحله انجام میگیرد.
در مرحلهی نخست، که به آن مرحلهی پیشرونده (Forward Process) گفته میشود، مدل یاد میگیرد چگونه یک تصویر واقعی را بهصورت تدریجی و مرحلهبهمرحله به نویز تبدیل کند. این فرایند عملاً شبیهسازی حرکت از یک حالت منظم به حالتی کاملاً آشفته است، مانند روند افزایش آنتروپی در ترمودینامیک، که سیستم بهسمت بینظمی بیشتر پیش میرود.

در مرحلهی دوم، که مرحلهی بازگشت یا فرایند معکوس (Reverse Process) نامیده میشود، مدل مسیر را برعکس طی میکند: از یک تصویر کاملاً نویزی آغاز میشود و تلاش میکند گامبهگام آن را به یک تصویر منسجم، واقعی و معنادار بازسازی کند. این بازسازی، مبتنی بر دانشی است که مدل در طول آموزش، از ساختار دادههای واقعی میآموزد و جوهرهی اصلی عملکرد الگوریتم انتشار را شکل میدهد.
وقتی مدل، میلیونها تصویر واقعی را ببیند و از آنها یاد بگیرد، به نقطهای میرسد که میتواند از دل هیچ، یعنی از یک تصویر کاملاً تصادفی، چیزهایی بسازد که هیچوقت وجود نداشتهاند: چهرههای جدید، مناظر تخیلی یا حتی نقاشیهایی شبیه به آثار هنرمندان بزرگ. جالبتر آنکه روش یادشده فقط محدود به تصویر نیست؛ از این الگوریتم میتوان برای تولید صدا، موسیقی و حتی ویدیو هم استفاده کرد.
الگوریتم بازپخت شبیهسازی شده برای جستوجوی هوشمند
بهاحتمال زیاد تابهحال با مسائلی روبهرو شدهاید که فقط یک پاسخ مشخص ندارند، بلکه چندین راهحل ممکن دارند؛ اما همهی آنها به یک اندازه خوب و کارآمد نیستند. بهعنوان مثال، تصور کنید میخواهید یک انبار بزرگ را بچینید. راههای زیادی برای چیدمان اجناس وجود دارند، ولی بعضی از آنها سریعتر، کمهزینهتر و بهینهتر عمل میکنند. اینجا است که الگوریتمی به نام الگوریتم بازپخت شبیهسازیشده (Simulated Annealing) وارد ماجرا میشود که نامش از علم فیزیک مواد میآید.
در متالورژی، برای کاهش نقصهای ریز در ساختار یک فلز، آن را بهتدریج گرم و سپس بهآرامی سرد میکنند تا به حالتی پایدارتر و کمانرژیتر برسد. الگوریتم بازپخت شبیهسازیشده هم از همین ایده الهام گرفته، با این تفاوت که بهجای اصلاح ساختار فلز، بهدنبال پیدا کردن بهترین پاسخ، میان مجموعهای از پاسخهای ممکن برای یک مسئله است.
فرض کنید میخواهید بلندترین قله را در میان رشتهکوهی پر از فراز و فرود پیدا کنید. یک روش ساده مثل الگوریتم تپهنوردی (Hill Climbing Algorithm) همیشه فقط بهدنبال مسیرهای صعودی میگردد، بنابراین شاید روی قلهای کوتاهتر، تصور کند به بالاترین نقطه رسیده، درحالیکه قلهای بلندتر در جای دیگری پنهان مانده است.
الگوریتم بازپخت برای حل این مشکل از یک ترفند هوشمندانه استفاده میکند: ابتدا با یک دمای بالا شروع میکند، بهطوریکه حتی اجازه میدهد راهحلهای ضعیفتر هم گاهی انتخاب شوند. این انعطاف به الگوریتم کمک میکند تا از درهها عبور کند و به قلههای بلندتر برسد. سپس، با گذر زمان و کاهش دما، احتمال پذیرفتن گزینههای نامطلوب کم میشود و الگوریتم، وارد مرحلهای میشود که فقط روی بهینهسازی دقیق، تمرکز میکند.
الگوریتم بازپخت شبیهسازیشده نشان میدهد که گاهی برای رسیدن به بهترین پاسخ، باید ابتدا کمی از مسیر خارج شویم
الگوریتم بازپخت شبیهسازیشده، فقط یک ایدهی نظری نیست؛ بلکه در مسائل واقعی بسیاری بهکار گرفته شده است. از طراحی تراشههای الکترونیکی و بهینهسازی مسیرهای حملونقل تا زمانبندی پروژهها، برنامهریزی تولید و حتی یادگیری ماشین. این الگوریتم، مخصوصاً در مسائلی که فضای پاسخ بسیار گسترده و پر از نقاط بهظاهر خوب ولی غیرایدئال است، عملکرد درخشانی دارد. در واقع، قدرت اصلی آن در این است که میتواند راهحلهایی را بیابد که الگوریتمهای سادهتر در آن گیر میکنند یا اصلاً آنها را نمیبینند.
جالب است که همین روند، یک استعارهی دقیق برای مسیر یادگیری برنامهنویسی هم بهشمار میآید. در آغاز راه، معمولاً با زبانها، ابزارها و تکنولوژیهای مختلف روبهرو میشوید، تجربه میکنید و مدام مسیرتان را تغییر میدهید؛ اما رفتهرفته، شناخت بهتری از علایق و تواناییهایتان پیدا میکنید و تمرکزتان را روی یک حوزهی مشخص میگذارید تا در آن متخصص شوید. درست مثل الگوریتم بازپخت شبیهسازی شده که ابتدا با آزمون و خطا پیش میرود، اما درنهایت به یک پاسخ پایدار و بهینه میرسد.
الگوریتم Sleep Sort برای مرتبسازی در خواب
نمیشود الگوریتمها را توضیح داد و حرفی از مرتبسازی نزد. یکی از عجیبترین و درعینحال بامزهترین الگوریتمهای مرتبسازی که تاکنون طراحی شده، الگوریتمی بهنام Sleep Sort است.
بیشتر الگوریتمهای مرتبسازی کلاسیک، از روشی به نام تقسیم و غلبه (Divide and Conquer) استفاده میکنند. یعنی اول مسئلهی اصلی را به چند زیرمسئلهی سادهتر تقسیم (تقسیم)، سپس هرکدام از این زیرمسئلهها را جداگانه حل (غلبه) و در نهایت جوابها را ترکیب میکنند تا به پاسخ نهایی برسند. بهعنوان مثال، الگوریتمهایی مثل مرتبسازی ادغامی (Merge Sort) و مرتبسازی سریع (Quick Sort) دقیقاً همین کار را میکنند تا بتوانند با سرعت و کارایی بالا، دادهها را مرتب کنند.
اگرچه Sleep Sort هیچگاه در دنیای واقعی کاربرد ندارد، الهامبخش مباحثی جذاب در طراحی سیستمهای زمانمند و تفکر خارج از چارچوب الگوریتمی بوده است
الگوریتم Sleep Sort اما مسیر کاملاً متفاوتی را طی میکند. این الگوریتم عجیب و خلاقانه، برای اولینبار در یکی از فرومهای اینترنتی معرفی شد و ساختاری بسیار ساده اما غیرمتعارف دارد. در الگوریتم Sleep Sort، برای هر عدد در آرایه، یک رشتهی (Thread) جداگانه راهاندازی میشود که بهمدت متناسب مقدار آن عدد میخوابد (sleep). وقتی خوابش تمام شد، عدد را چاپ میکند.
بهعنوان مثال، اگر در آرایهای اعداد ۳، ۱ و ۵ داشته باشید، رشتهی مربوط به عدد ۱ فقط یک واحد زمانی میخوابد و زودتر از بقیه بیدار میشود و عددش را چاپ میکند. عدد ۳ کمی بعدتر و عدد ۵ آخر از همه. نتیجه؟ اعداد بهطور خودکار بهترتیب صعودی چاپ میشوند.
این روش فوقالعاده زیرکانه به نظر میرسد، چون کار مرتبسازی را به زمانبندی CPU واگذار میکند؛ اما درعینحال غیرعملی و بیفایده است، زیرا هیچکدام از کامپیوترهای جدی دنیا واقعاً از این روش برای مرتبسازی دادهها استفاده نمیکنند.
الگوریتم Sleep Sort بیشتر شبیه به یک شوخی هوشمندانه در دنیای برنامهنویسی به نظر میرسد. چرا غیرعملی است؟ چون زمانبندی دقیق در کامپیوترها قابل اعتماد نیست و اگر چند عدد نزدیک به هم باشند، احتمالاً ترتیب اشتباه شود.
الگوریتم مرتبسازی ساختگی (Bogo Sort)
یکی از سادهترین و درعینحال بیفایدهترین الگوریتمهای مرتبسازی که بیشتر جنبهی طنز دارد، الگوریتمی است بهنام مرتبسازی ساختگی (Bogo Sort). این الگوریتم بدون هیچ منطق خاصی، عناصر یک آرایه (لیست) را بارها و بارها بهشکل کاملاً تصادفی جابهجا میکند و هر بار بررسی میکند که آیا آرایه مرتب شده یا نه. اگر مرتب شده باشد، کار تمام است؛ اگر نه، دوباره یک چیدمان کاملاً تصادفی جدید امتحان میشود.
در نگاه اول، این روش کاملاً ناکارآمد بهنظر میرسد و واقعاً هم همینطور است. برای مرتبسازیِ حتی یک لیست نسبتاً کوچک، این الگوریتم شاید به سالها زمان نیاز داشته باشد؛ چون هیچ نشانهای از بهبود یا جهتگیری در روند ندارد و تنها به شانس بستگی دارد.
اکنون فرض کنید این ایده را با یکی از نظریههای مطرح در فیزیک مدرن ترکیب کنیم: نظریهی چندجهانی (Multiverse Theory). نظریهی مذکور میگوید که برای هر نتیجهی ممکن، جهانی موازی وجود دارد که در آن، آن نتیجه واقعاً اتفاق افتاده؛ یعنی اگر در این جهان، آرایهی ما مرتب نیست، احتمالاً در یک جهان دیگر همان آرایه بهطور تصادفی مرتب شده است.

اگر بتوانیم بهنحوی به این جهانهای موازی دسترسی داشته باشیم، میتوانیم نسخههایی از مسئله را در آنها بررسی کنیم و آن نسخهای را که در آن آرایه مرتب شده است، انتخاب کنیم. در این صورت، بهجای امتحان میلیونها چیدمان در همین جهان، فقط باید آن جهان خاص را پیدا کنیم که پاسخ در آن از قبل آماده است.
ایدهی تخیلی مرتبسازی ساختگی کوانتومی (Quantum Bogo Sort) همینجا شکل میگیرد: فرض بر این است که الگوریتم بتواند بهطور کوانتومی تمام حالتهای ممکن را بهطور همزمان بررسی کند، و سپس تنها نتیجهای را که در آن آرایه مرتب است، انتخاب کند. البته این فراتر از توان فعلی فناوری است و بیشتر در حد طنز و فلسفهی علم مطرح میشود.
در نهایت، این الگوریتم نشان میدهد که برخی مسائل را نمیتوان صرفاً با شانس یا آزمون کورکورانه حل کرد؛ بلکه نیاز به درک ساختار مسئله، الگوریتمهای بهینه و روشهایی هوشمندانهتر داریم.
الگوریتم RSA؛ امنیت دیجیتال در برابر تهدید کوانتوم
الگوریتم Rivest-Shamir-Adleman یا الگوریتم RSA یکی از مهمترین و کاربردیترین الگوریتمهای رمزنگاری در دنیای دیجیتال است. تقریباً هر بار که شما در اینترنت خرید میکنید یا وارد یک سایت امن میشوید، RSA از اطلاعات شما محافظت میکند.
RSA چطور کار میکند؟ اصل ماجرا بسیار ساده اما درعینحال عمیق است: ضرب دو عدد اول خیلی بزرگ، کار راحتی است؛ اما اگر فقط حاصل ضرب را داشته باشید، پیدا کردن دو عدد اول خیلی سخت و زمانبر میشود.
این مسئله بهقدری سخت است که حتی سریعترین کامپیوترهای کلاسیک هم برای شکستن رمز RSA به میلیاردها سال زمان نیاز دارند. دقیقتر بگوییم، رمزگشایی یک کلید ۲۰۴۸ بیتی میتواند حدود ۳۰۰ تریلیون سال زمان ببرد.
گاهی بدترین الگوریتمها، بهترین الهامها را برای درک محدودیتهای محاسباتی و خیالپردازی علمی فراهم میکنند
در روش RSA هر کسی میتواند با کلید عمومی برای شما پیامی رمزگذاریشده بفرستد، ولی فقط شما با کلید خصوصی خودتان میتوانید آن را باز کنید. بههمینخاطر به آن رمزنگاری با کلید عمومی میگویند. همین اصل ساده، امنیت کل اینترنت را فراهم کرده است؛ اما این امنیت، شاید برای همیشه باقی نماند. چون اگر روزی کامپیوترهای کوانتومی واقعاً قدرتمند شوند، الگوریتمی بهنام شور (Shor) وارد میدان میشود، الگوریتمی که توانایی آن را دارد تا در زمانی بسیار کوتاه، تجزیهی سخت اعداد را انجام دهد.
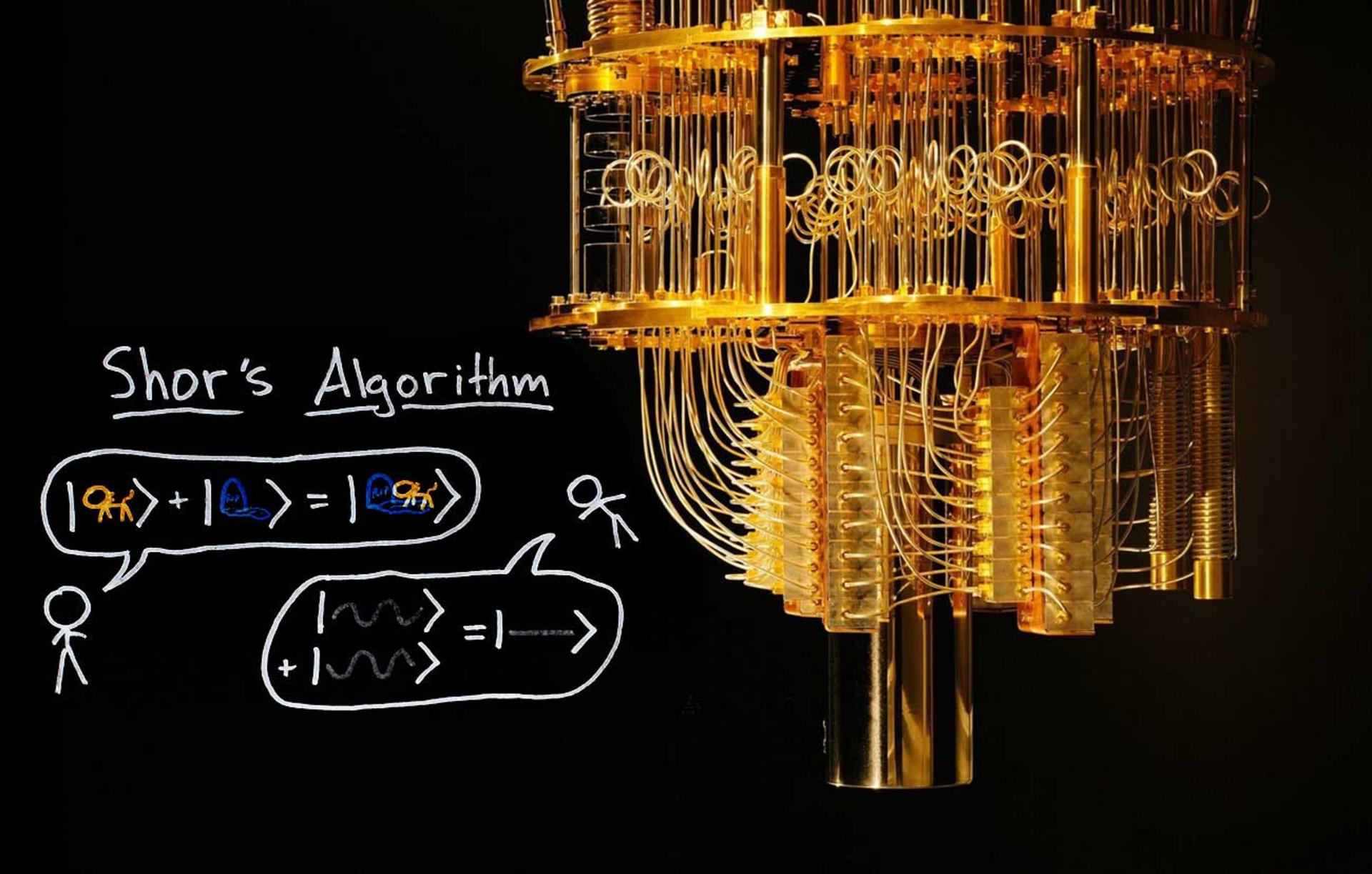

شور از ویژگیهای عجیبی مثل برهمنهی، درهمتنیدگی و محاسبات موازی در دنیای کوانتومی استفاده میکند تا کاری را که برای یک لپتاپ معمولی میلیاردها سال طول میکشد، در چند ثانیه انجام دهد.
البته فعلاً جای نگرانی نیست. درحالحاضر، حتی پیشرفتهترین رایانههای کوانتومی هم موفق نشدهاند عدد ۳۵ را بهدرستی تجزیه کنند؛ اما اگر روزی الگوریتم شور روی یک کامپیوتر کوانتومی قدرتمند اجرا شود، آن وقت کل دنیای امنیت سایبری ممکن است زیر و رو شود.
الگوریتم Marching Cubes برای ساخت مدل سهبعدی بدن
وقتی از اسکن مغز یا بدن حرف میزنیم، دادهها معمولاً بهصورت لایههای دوبعدی ثبت میشوند؛ اما چطور میتوان از این لایهها، یک تصویر سهبعدی واقعی ساخت؟ اینجاست که الگوریتمی بهنام Marching Cubes (مکعبهای پیشرونده) وارد عمل میشود.
بیایید فضای داخل بدن را بهصورت یک شبکهی سهبعدی از نقطهها تصور کنیم. در هر نقطه، یک عدد داریم که نشان میدهد شدت یک ویژگی مثل چگالی بافت یا شدت تصویر در آن قسمت چقدر است. الگوریتم Marching Cubes این نقاط را یکییکی بررسی میکند و هر بار با هشت نقطهی اطرافش یک مکعب فرضی میسازد.
درون هر مکعب، بسته به اینکه مقادیر عددیاش بالاتر یا پایینتر از یک آستانهی مشخصی باشند، الگوریتم تصمیم میگیرد که چه شکلی باید رسم شود. چون هر گوشه میتواند روشن یا خاموش باشد، در مجموع ۲۵۶ حالت مختلف وجود دارند و برای هر حالت، یک شکل هندسی از پیش محاسبهشده داریم. الگوریتم این شکلها را یکییکی کنار هم میچیند و در نهایت، یک سطح سهبعدی منسجم میسازد که میتوان آن را در نرمافزارهای گرافیکی یا پزشکی نمایش داد. همین روش انقلابی، راه را برای تصویرسازی سهبعدی از دادههای پزشکی هموار کرد.
تصویر بالا را ببینید. هر مکعب در الگوریتم Marching Cubes از ۸ رأس تشکیل شده است که میتوانند روشن یا خاموش (۱ یا ۰) باشند. این وضعیتها در قالب یک عدد باینری ذخیره میشوند و چون ۲⁸ برابر با ۲۵۶ است، این الگوریتم میتواند ۲۵۶ حالت متفاوت برای استخراج سطوح ایزویی (isosurfaces) تولید کند.
الگوریتم PBFT برای امنیت بلاکچین
بیایید کمی وارد دنیای استراتژی شویم. فرض کنید چند ژنرال بیزانسی، شبانه دور یک شهر اردو زدهاند و باید باهم بهصورت هماهنگ حمله کنند؛ اما اگر یکی از ژنرالها گیج شود، دیر برسد یا عمداً خرابکاری کند، چه اتفاقی میافتد؟ بقیهی ژنرالها نمیدانند به او اعتماد کنند یا نه و شاید کل نقشه، شکست بخورد. این وضعیت که میتواند کل عملیات را خراب کند، در دنیای علم به مسئلهی ژنرالهای بیزانسی معروف شده است.
اما این فقط داستانی تاریخی نیست. در دنیای امروز، این معضل در شبکههای توزیعشده مثل بلاکچین یا پایگاههای دادهی ابری هم وجود دارد. فرض کنید چند کامپیوتر باید با هم تصمیمی مشترک بگیرند، ولی یکی از آنها خراب شود یا رفتار عجیبی نشان دهد. حالا چطور میتوانیم مطمئن شویم که بقیهی سیستم، با وجود این نقص، همچنان درست کار میکند؟
الگوریتمهایی مثل تحمل خطای بیزانسی عملی (Practical Byzantine Fault Tolerance یا PBFT) برای همین طراحی شدهاند. در این الگوریتم، یک نود (گره)، پیامی برای بقیه میفرستد تا آمادگیاش را اعلام کند. اگر اکثریت گرهها تأیید کنند، یک اجماع شکل میگیرد و همه با هم، تغییرات را اعمال میکنند. این یعنی حتی اگر یکسوم سیستم از کار بیفتد، بقیه میتوانند بدون مشکل به کارشان ادامه دهند.
این الگوریتمها زیربنای امنیت و هماهنگی در فناوریهایی مثل بلاکچین و سیستمهای ابری هستند. در واقع، بدون آنها خیلی از سرویسهای آنلاین قابل اعتماد نبودند.
الگوریتم Boids برای شبیهسازی پرواز پرندگان
یکی از شگفتانگیزترین تواناییهای برخی الگوریتمها، تقلید از رفتارهای طبیعی است، طوری که گویی قوانین پنهان طبیعت در قالب چند خط کد بازنویسی شدهاند. در سال ۱۹۸۶، برنامهای به نام Boids نوشته شد که پرواز دستهجمعی پرندگان را نه با دستورهای پیچیده، بلکه فقط با سه قانون ساده و الهامگرفته از طبیعت، شبیهسازی میکرد:
- پرندهها نباید بیشازحد به هم نزدیک شوند (جلوگیری از برخورد).
- هر پرنده سعی میکند همراستا با بقیهی گروه پرواز کند.
- هر پرنده به سمت مرکز دستهی خودش متمایل میشود.
همین و بس. ولی نتیجه؟ پرندگانی مجازی که دقیقاً مثل یک دستهی واقعی پرواز میکنند؛ بدون هیچ فرمان مرکزی، بدون هوش مصنوعی پیچیده، فقط با رعایت این سه اصل ساده. الگوریتم Boids یکی از بهترین نمونههایی است که نشان میدهد حتی سادهترین قوانین، اگر در کنار هم درست کار کنند، میتوانند رفتارهایی حیرتانگیز و شبیه به زندگی واقعی خلق کنند.
الگوریتم Boyer-Moore برای برنامهنویسها
یکی از درخشانترین الگوریتمهایی که برنامهنویسها با آن سروکار دارند، الگوریتم Boyer–Moore است؛ روشی سریع، هوشمند و بهطرز عجیبی کارآمد، بهویژه وقتی با متنهای بلند طرف باشیم. برخلاف تصور، این الگوریتم هرچه متن طولانیتر باشد، عملکرد بهتری دارد.
درحالیکه بسیاری از الگوریتمهای جستوجو از چپ به راست حرکت میکنند و همهچیز را دانهبهدانه بررسی میکنند، Boyer–Moore راهی متفاوت در پیش میگیرد: متن را از راست به چپ میخواند و بهجای اینکه روی هر حرف مکث کند، در صورت ناهماهنگی، پرش میکند، آن هم نه یک یا دو خانه، بلکه گاهی چند حرف را هوشمندانه نادیده میگیرد.
Boyer–Moore الگوریتمی است که بهجای بررسی خطبهخط متن، با پیشبینی هوشمندانه و پرشهای هدفمند، جستوجو را از یک فرایند خطی به یک شکار سریع و دقیق تبدیل میکند
این عملکرد شگفتانگیز از دو جدول سرچشمه میگیرد که قبل از شروع جستوجو آماده میشوند:
- جدول اول نشان میدهد در صورت مشاهدهی یک کاراکتر نامرتبط، الگوریتم چقدر میتواند جلو بپرد.
- جدول دوم زمانی بهکار میآید که بخشی از کلمه درست پیش رفته ولی در ادامه خطا رخ داده است. این جدول کمک میکند تا الگوریتم بدون بررسیهای تکراری، از همان جایی که احتمال موفقیت بیشتری دارد، ادامه دهد.
نتیجهی این طراحی هوشمندانه چیست؟ در بسیاری از موارد، الگوریتم اصلاً نیازی به خواندن کامل متن ندارد. بلکه با کمترین بررسی، مستقیماً بهدنبال هدف میرود. ابزارهایی مثل grep در لینوکس از این الگوریتم یا نسخههای بهبودیافتهی آن استفاده میکنند و بههمیندلیل بسیار سریع عمل میکنند. پشتصحنهی آنها، الگوریتم Boyer–Moore ایستاده است: الگوریتمی که وقت تلف نمیکند.
در دنیای الگوریتمها، هر خط کد میتواند نمایندهی یک ایدهی عمیق علمی، یک مدل از طبیعت یا حتی یک نگاه فلسفی به جهان باشد. از الگوریتمهایی که از نظریهی کوانتوم الهام گرفتهاند تا روشهایی که رفتار پرندگان را بازآفرینی میکنند، میبینیم که هوش انسانی چگونه توانسته از مفاهیم پیچیدهی فیزیک، زیستشناسی و ریاضیات، ابزارهایی بسازد که کارشان فقط محاسبه نیست، بلکه بازسازی نظم و معنا در دل بینظمی دادهها است.
الگوریتمها صرفاً راهحلهایی برای مسائل مهندسی نیستند؛ بلکه پلهایی میان تخیل و فناوری، میان بازی و واقعیت و میان دادههای خام و تجربهی انسانی هستند. آنها نشان میدهند که برنامهنویسی فقط نوشتن دستور نیست، بلکه نوعی تفکر است؛ تفکری که میتواند صدا بسازد، تصویر بیافریند، امنیت فراهم کند یا حتی نظم را از دل تصادف بیرون بکشد. هر الگوریتم، ما را یک گام به فهم بهتر این واقعیت نزدیکتر میکند: دنیای دیجیتال، بازتابی از قدرت اندیشهی ما برای شکل دادن به آینده است.